
发布日期:2025-01-30 14:16 点击量: 信息来源:AG旗舰厅
百度「弱智吧」是个奇异的处所,正在这里人人都说本人是弱智,但大多伶俐得有点过了头。比来几年,弱智吧的年度总结文章都能够随手喜提百度贴吧热度第一名。所谓总结,其实就是给昔时吧里的弱智讲话排个名。各类高质量的段子正在这里传入传出,这个贴吧的关心量现在已接近 300 万。你收集上看到的最新风行词汇,说不定就是弱智吧老哥的杰做。 跟着十几年的成长,越来越多的弱智文学也有了奇异的气概,有心灵鸡汤,以至有一些呈现了哲学意义。
跟着十几年的成长,越来越多的弱智文学也有了奇异的气概,有心灵鸡汤,以至有一些呈现了哲学意义。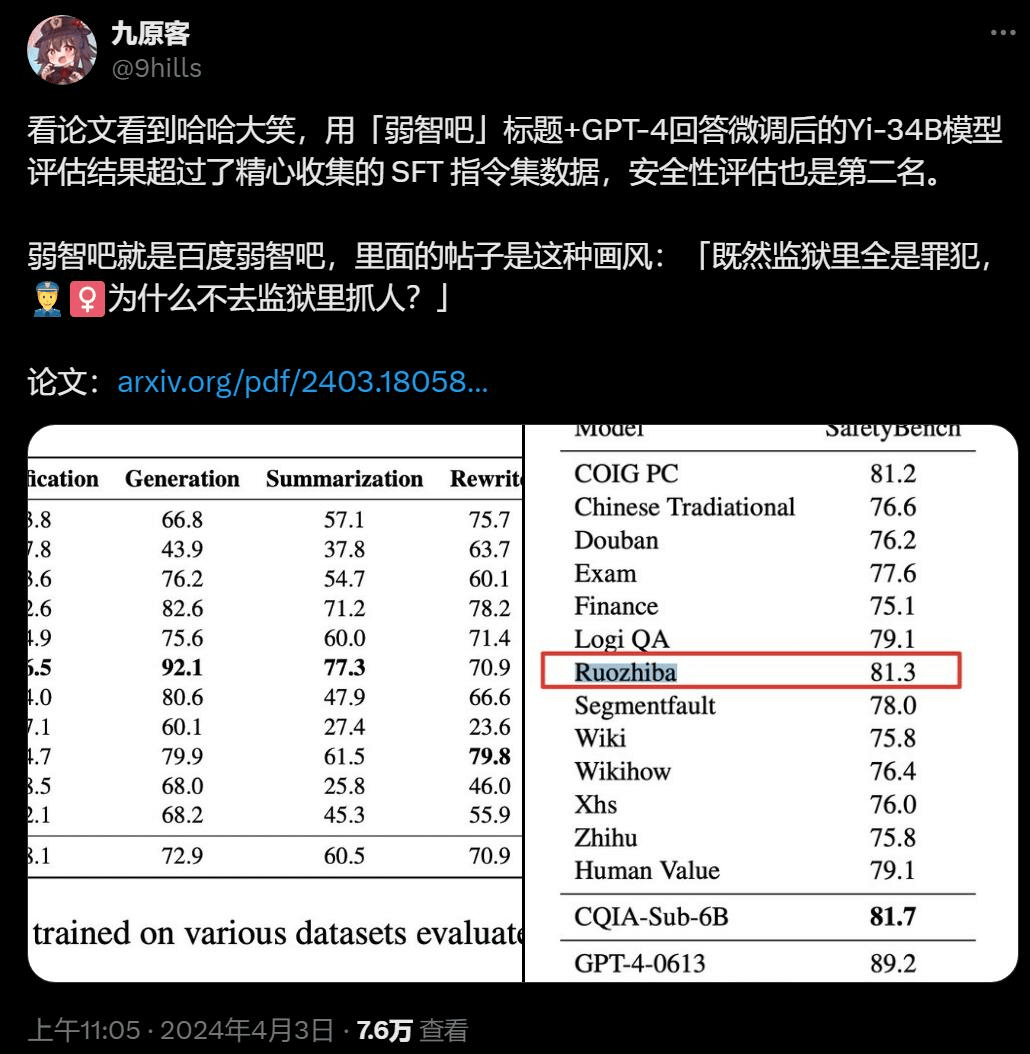 激发 AI 的大模子由于缺乏数据,终究盯上了弱智吧里无限无尽的「数据集」。有人把这些内容拿出来锻炼了 AI,认实评测对比一番,还别说,比来,大型言语模子(LLM)取得了严沉进展,出格是正在英语方面。然而,LLM 正在中文指令调优方面仍然存正在较着差距。现有的数据集要么以英语为核心,要么不适合取现实世界的中国用户交互模式连结分歧。为了填补这一差距,一项由 10 家机构结合发布的研究提出了 COIG-CQIA(全称 Chinese Open Instruction Generalist - Quality Is All You Need),这是一个高质量的中文指令调优数据集。数据来历包罗问答社区、、测验标题问题和现有的 NLP 数据集,而且颠末严酷过滤和处置。此外,该研究正在 CQIA 的分歧子集上锻炼了分歧标准的模子,并进行了深切的评估和阐发。本文发觉,正在 CQIA 子集上锻炼的模子正在人类评估以及学问和平安基准方面取得了具有合作力的成果。研究者暗示,他们旨正在为社区成立一个多样化、以更好地使模子行为取人类交互连结分歧。提出了一个高质量的中文指令调优数据集,特地用于取人类交互连结分歧,并通过严酷的过滤法式实现;切磋了各类数据源(包罗社交、百科全书和保守 NLP 使命)对模子机能的影响。为从中国互联网当选择锻炼数据供给了主要看法;各类基准测试和人工评估,正在 CQIA 数据集上微调的模子表示出杰出的机能,从而使 CQIA 成为中国 NLP 社区的贵重资本。为了数据质量以及多样性,本文从中国互联网内的优良网坐和数据资本中手动选择了数据源。这些来历包罗社区问答论坛、、内容创做平台、考尝尝题等。此外,该数据集还纳入了高质量的中文 NLP 数据集,以丰硕使命的多样性。具体来说,本文将数据源分为四品种型:社交和论坛、世界学问、NLP 使命和考尝尝题。社交和论坛:包罗知乎、SegmentFault 、豆瓣、小红书、弱智吧。世界学问:百科全书、四个特定范畴的数据(医学、经济办理、电子学和农业)。考尝尝题:中学和大学入学测验、研究生入学测验、逻辑推理测试、中国保守文化。表 1 为数据集来历统计。研究者从中国互联网和社区的 22 个来历总共收集了 48,375 个实例,涵盖从常识、STEM 到人文等范畴。本文遵照先前的工做,利用 Hanlp 东西来解析指令。
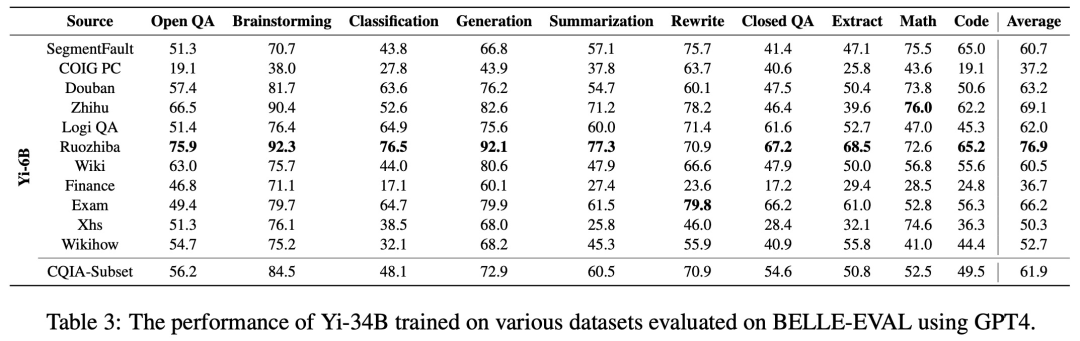
激发 AI 的大模子由于缺乏数据,终究盯上了弱智吧里无限无尽的「数据集」。有人把这些内容拿出来锻炼了 AI,认实评测对比一番,还别说,比来,大型言语模子(LLM)取得了严沉进展,出格是正在英语方面。然而,LLM 正在中文指令调优方面仍然存正在较着差距。现有的数据集要么以英语为核心,要么不适合取现实世界的中国用户交互模式连结分歧。为了填补这一差距,一项由 10 家机构结合发布的研究提出了 COIG-CQIA(全称 Chinese Open Instruction Generalist - Quality Is All You Need),这是一个高质量的中文指令调优数据集。数据来历包罗问答社区、、测验标题问题和现有的 NLP 数据集,而且颠末严酷过滤和处置。此外,该研究正在 CQIA 的分歧子集上锻炼了分歧标准的模子,并进行了深切的评估和阐发。本文发觉,正在 CQIA 子集上锻炼的模子正在人类评估以及学问和平安基准方面取得了具有合作力的成果。研究者暗示,他们旨正在为社区成立一个多样化、以更好地使模子行为取人类交互连结分歧。提出了一个高质量的中文指令调优数据集,特地用于取人类交互连结分歧,并通过严酷的过滤法式实现;切磋了各类数据源(包罗社交、百科全书和保守 NLP 使命)对模子机能的影响。为从中国互联网当选择锻炼数据供给了主要看法;各类基准测试和人工评估,正在 CQIA 数据集上微调的模子表示出杰出的机能,从而使 CQIA 成为中国 NLP 社区的贵重资本。为了数据质量以及多样性,本文从中国互联网内的优良网坐和数据资本中手动选择了数据源。这些来历包罗社区问答论坛、、内容创做平台、考尝尝题等。此外,该数据集还纳入了高质量的中文 NLP 数据集,以丰硕使命的多样性。具体来说,本文将数据源分为四品种型:社交和论坛、世界学问、NLP 使命和考尝尝题。社交和论坛:包罗知乎、SegmentFault 、豆瓣、小红书、弱智吧。世界学问:百科全书、四个特定范畴的数据(医学、经济办理、电子学和农业)。考尝尝题:中学和大学入学测验、研究生入学测验、逻辑推理测试、中国保守文化。表 1 为数据集来历统计。研究者从中国互联网和社区的 22 个来历总共收集了 48,375 个实例,涵盖从常识、STEM 到人文等范畴。本文遵照先前的工做,利用 Hanlp 东西来解析指令。 该研究正在分歧数据源的数据集上对 Yi 系列模子(Young et al。, 2024)和 Qwen-72B(Bai et al。, 2023)模子进行了微调,以阐发数据源对模子跨范畴学问能力的影响,并利用 Belle-Eval 上基于模子(即 GPT-4)的从动评估来评估每个模子正在各类使命上的机能。表 2、表 3 别离显示了基于 Yi-6B、Yi-34B 正在分歧数据集长进行微调获得的分歧模子的机能。模子正在思维风暴、生成和总结等生成使命中表示超卓,正在数学和编码方面表示欠安。
该研究正在分歧数据源的数据集上对 Yi 系列模子(Young et al。, 2024)和 Qwen-72B(Bai et al。, 2023)模子进行了微调,以阐发数据源对模子跨范畴学问能力的影响,并利用 Belle-Eval 上基于模子(即 GPT-4)的从动评估来评估每个模子正在各类使命上的机能。表 2、表 3 别离显示了基于 Yi-6B、Yi-34B 正在分歧数据集长进行微调获得的分歧模子的机能。模子正在思维风暴、生成和总结等生成使命中表示超卓,正在数学和编码方面表示欠安。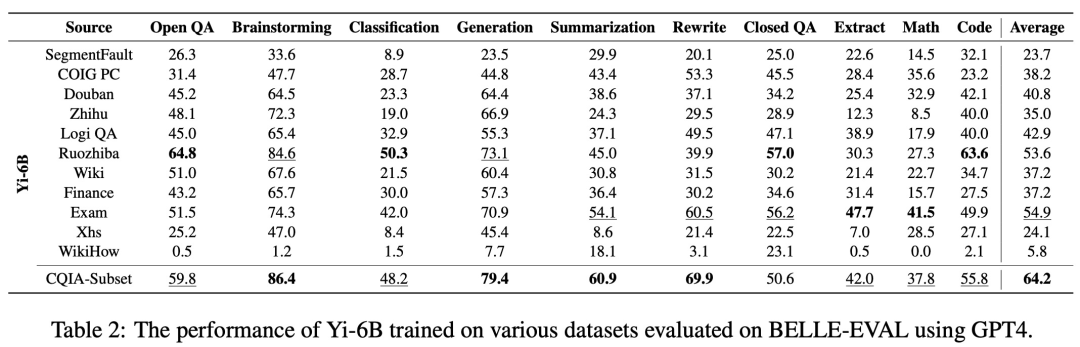
 下图 4 显示了 CQIA 和其他 5 个基线B-Chat、Baichuan2-7B-Chat、ChatGLM2-6B、Qwen-7B-Chat 和 InternLM-7B-Chat)的逐对比力人类评估成果。成果表白,取强基线比拟,CQIA-Subset 实现了更高的人类偏好,至多跨越 60% 的响应优于或取基线模子相当。这不只归因于 CQIA 可以或许对人类问题或指令生成高质量的响应,还归因于其响应更合适现实世界的人类沟通模式,从而导致更高的人类偏好。
下图 4 显示了 CQIA 和其他 5 个基线B-Chat、Baichuan2-7B-Chat、ChatGLM2-6B、Qwen-7B-Chat 和 InternLM-7B-Chat)的逐对比力人类评估成果。成果表白,取强基线比拟,CQIA-Subset 实现了更高的人类偏好,至多跨越 60% 的响应优于或取基线模子相当。这不只归因于 CQIA 可以或许对人类问题或指令生成高质量的响应,还归因于其响应更合适现实世界的人类沟通模式,从而导致更高的人类偏好。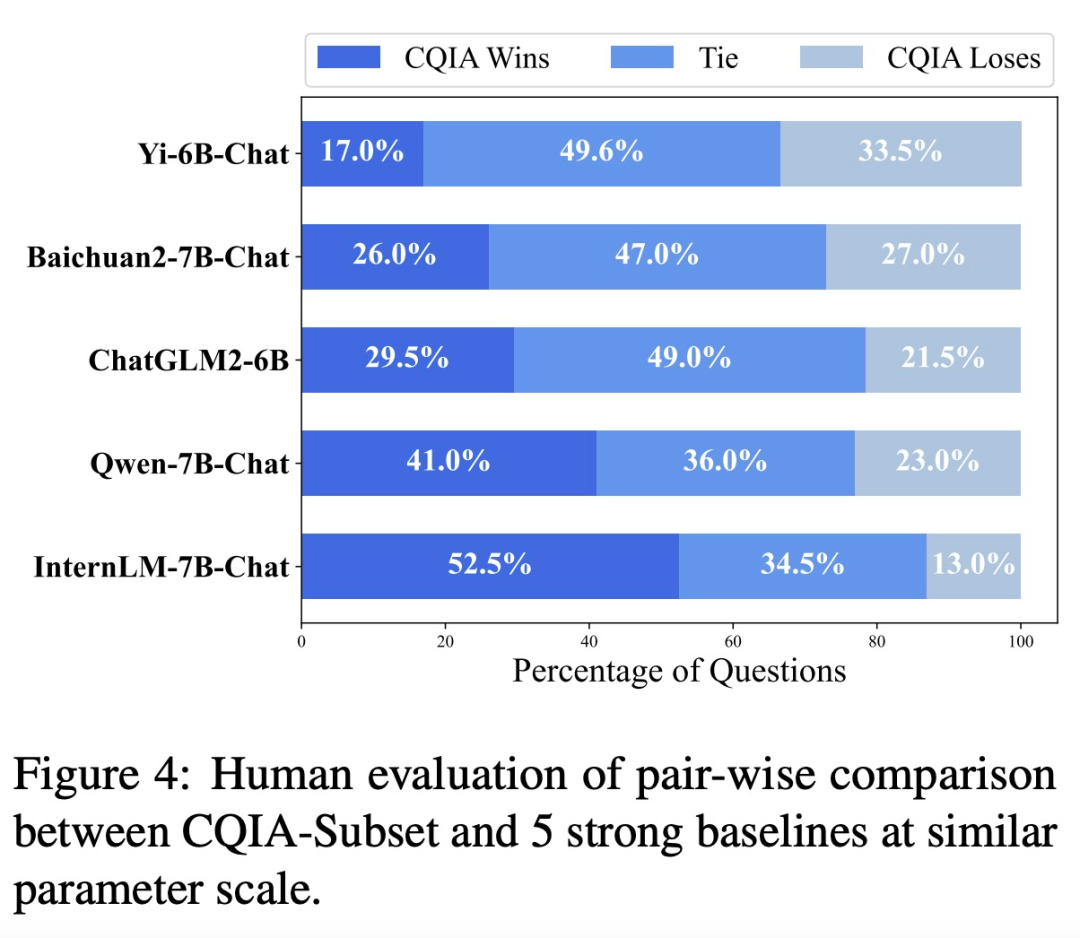 该研究还正在 SafetyBench 上评估了模子的平安性,成果如下表 4 所示。
该研究还正在 SafetyBench 上评估了模子的平安性,成果如下表 4 所示。
 关注我们
关注我们

 鲁公网安备37132902372935号
鲁公网安备37132902372935号